At Cro Metrics, we talk about this with clients all the time: “If the A/B test win was statistically significant, how can we be sure the performance will hold?”
Fair question. And it gets to the heart of a bigger challenge in experimentation: just because a test looks like a win doesn’t mean it’ll hold up over time.
Measuring long-term impact isn’t as simple as flipping a switch. Audience behavior shifts. Traffic ebbs and flows. Outside variables sneak in. Suddenly, that “clear win” starts to look a lot murkier.
This is why we don’t stop our analysis when the test ends.
To ensure our recommendations drive lasting impact, not just temporary lifts, we’ve developed a rigorous post-test validation process using a Causal Impact model. This approach helps us answer the critical question: Did the change we tested actually cause the long-term result, or is something else going on?
Moving Beyond the A/B Test
A/B tests are still the most reliable way to measure incremental improvements but they operate within a tightly controlled window. Once a winning variant is deployed to 100% of users, real-world conditions introduce complexity—and that’s where our post-test methodology kicks in.
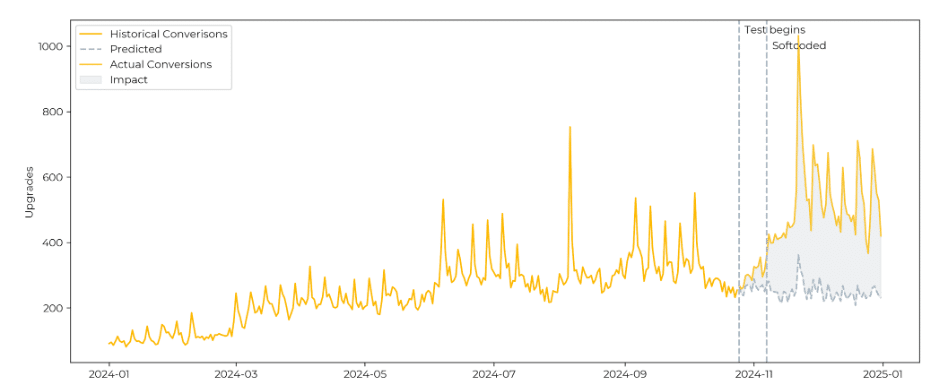
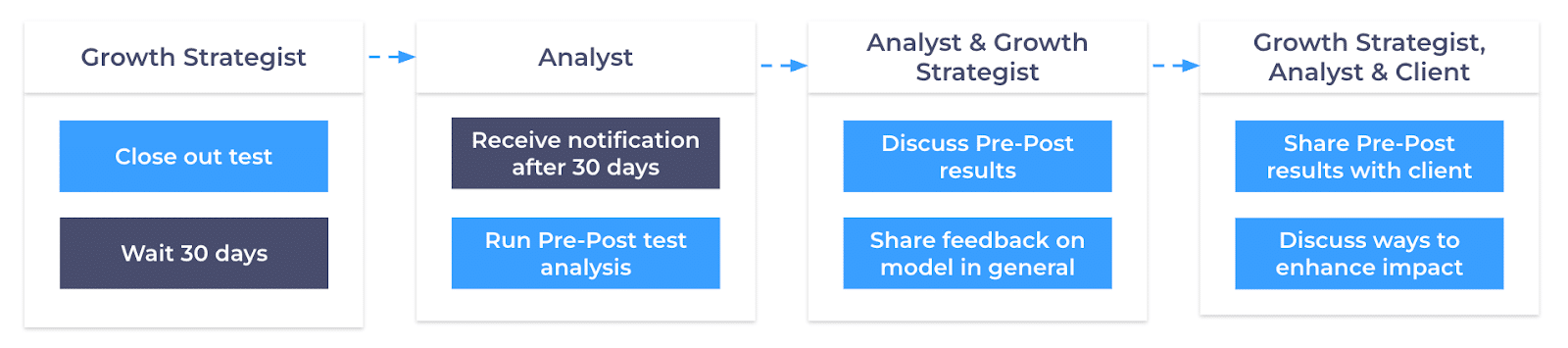
After 30 days of full traffic rollout, we run a “pre-post” analysis leveraging Causal Impact. This model estimates what performance should have looked like had no change been made then it compares it to what actually happened. This allows us to separate the true impact of the change from all the noise that comes with real-world conditions.
Uncovering Hidden Influences
Let’s look at a real-world example. In a test for a travel-related upsell modal, we saw strong results during the A/B phase. But after rollout, performance unexpectedly dipped. Was the test result invalid?
Not at all.
Our model identified a specific inflection point—October 10—where the actual results diverged from our predictions. So we dug deeper.
Investigating further, we found a shift in traffic mix: a partner site began sending lower-converting traffic to the same page, skewing results.
To validate this insight, we re-ran our model excluding data from that partner channel. The improvement reappeared, confirming that the test itself was effective—but its perceived underperformance was due to external traffic dilution.
Once we identified that the influx of low-converting visitors from the partner site was skewing results, we were able to collaborate with the client to deliver more relevant content to these users. By refining the experience for this specific traffic source, we not only safeguarded the original test’s gains but also unlocked a new opportunity to tailor messaging for a segment with distinct needs.
This kind of forensic follow-up is vital. Without it, meaningful wins could be mistakenly dismissed or misattributed, or worse, send your testing roadmap in the wrong direction.
It’s Not Just About Proving Value—It’s About Creating More Of It
Our goal isn’t simply to justify previous results. Post-test monitoring helps us find opportunities to refine strategy across channels and surface new growth levers. Whether adjusting traffic sources, aligning messaging, or optimizing specific user segments, this ongoing analysis drives compounding value over time.
Why It Matters
In today’s data-rich environment, stakeholders demand accountability—and rightly so. But without a clear understanding of why performance shifts post-test, it’s all too easy to misread the signal or chase the wrong one entirely.
Cro Metrics’ commitment to statistical rigor ensures our recommendations remain grounded, even after the test concludes. By modeling causality—not just correlation—we give our clients the confidence to act on results that truly move the needle.
If you want experimentation that stands up to scrutiny—and drives repeatable outcomes—this is the level of discipline it requires.