
At Cro Metrics, we have run tens of thousands of experiments over the years. That depth of data is a huge advantage. It also creates a very real problem that most growth teams eventually face: the more experiments you have, the harder it becomes to actually use what you have learned.
Patterns get buried. Context fades. Teams rely on memory, tribal knowledge, and whoever happens to still be around. When people leave, a lot of that understanding leaves with them. What remains is often locked behind primitive search tools, inconsistent documentation, or presentations that only answer very limited questions and surface few insights.
The answers are usually in the data. The problem has always been finding them.
Ask Iris started as a way to unlock that institutional knowledge.
We needed a system that could reason across our full experimentation history in a way that was accurate, fast, and secure. Simply connecting an LLM to a primitive RAG data store was not going to cut it.
We are building Ask Iris in the open. This post walks through the architectural choices and lessons that helped us get there.
Part 1: From Verbose Experiment Data to Useful Retrieval
The Problem: Too Much Detail Becomes Noise
Experiment data is naturally verbose. A single test often includes:
- A long hypothesis and background
- Detailed specs and designs
- Notes from multiple stakeholders
- Results and post-test analysis
If you take all of that and push it directly into a vector database, retrieval quality suffers. You do not get better answers. You get vague ones.
The Solution: AI-Driven Pre-Processing
 Instead of syncing raw experiment records straight from MySQL into a vector store, we built a processing loop designed specifically for experimentation data.
Instead of syncing raw experiment records straight from MySQL into a vector store, we built a processing loop designed specifically for experimentation data.
1. AI Summarization as a First-Class Step
Each experiment is first passed through an LLM that extracts the core of the test:
- What was the hypothesis?
- What changed between control and variant?
- What happened as a result?
- How can we classify this experiment to improve results (i.e. metadata)?
This creates a clean, consistent semantic summary while preserving the original data for reference and improving retrieval accuracy.
2. One Experiment, One Chunk
Many RAG systems split documents into arbitrary chunks. Because our data is already summarized, we can enforce a simple rule: one experiment equals one chunk.
This improves precision and avoids answers that incorrectly blend multiple tests together.
3. Why We Chose Qdrant
We use Qdrant as our vector database, and it has been a great fit for this problem.
Qdrant offers a set of features that were particularly important for our use case:
- 100% API-driven platform
- Support for text-based structured payloads (instead of docs only)
- Precise metadata filtering by fields like date, client, industry, or test type
That combination lets Ask Iris retrieve extremely accurate answers, not just something loosely related.
Part 2: Designing the Brain of Ask Iris
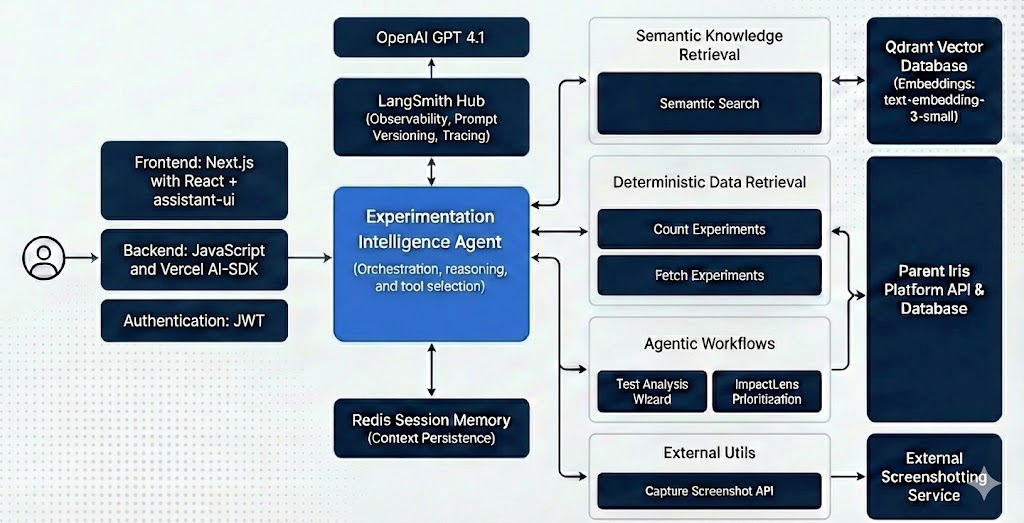 We needed a stack that let us move quickly while still giving us deep visibility into how the system behaved.
We needed a stack that let us move quickly while still giving us deep visibility into how the system behaved.
Frontend and Orchestration
We did not want to spend time building a chat UI from scratch, so we used assistant-ui. It is an open-source, enterprise-grade tool that covers the table-stakes UX, allowing us to focus our time on the intelligence and tooling layers.
For orchestration, we leaned on Vercel’s AI SDK. It made streaming responses, tool calling, and model coordination in React/Typescript much easier than rolling our own solutions.
Letting Subject Matter Experts Tune the System
Any product manager who has built AI-enabled tools knows that prompt tuning can be one of the hardest parts of a project.
In past projects, we learned that engineers are not always the right people to tune product-integrated prompts. Subject matter experts are much better positioned to do this work.
LangSmith changed how we worked:
- SMEs could manage, version, and test prompts safely in staging
- We could compare different prompts, models, and parameters side by side
- We gained full visibility into reasoning steps, tool calls, and intermediate outputs
From a product perspective, this was critical. If you cannot iterate on prompts quickly or inspect how an AI system behaves, progress slows and blind spots multiply. LangSmith made that level of visibility and iteration possible.
Choosing the Right Model
We tested several high-reasoning models. While impressive, many took 30 seconds or more to respond. That does not work for a conversational product.
We landed on GPT-4.1 because it offers a strong balance of intelligence, speed, and predictability. It also handles tool use particularly well, even when those tools have a large number of parameters and configuration options. This is an area where GPT-4o consistently struggled for our use case.
The main limitation we have encountered so far with GPT-4.1 is with long, multi-step workflows, where it can start to lose the thread. We addressed this by delegating narrower tasks to specialized sub-agents, which keeps the primary interaction fast and responsive.
Speed matters to users. It directly affects perceived value, engagement, and whether a tool becomes part of someone’s daily workflow. That reality played a major role in why we landed here.
What Ask Iris Can Actually Do
An agent is only as useful as the tools it can use. Ask Iris is not just answering questions. It is doing work.
Semantic and Deterministic Search
- Semantic search to find similar experiments, themes, or ideas
- Deterministic search to count tests, filter by attributes, or retrieve exact records
This hybrid approach avoids answers that sound plausible but are not precise.
Agentic Workflows
Test Analysis Wizard
Ask Iris can review test details, designs, and raw results, then draft an end-of-test report that strategists can refine.
ImpactLens Prioritization
Ask Iris connects directly to ImpactLens, our prioritization system powered by predictive modelling, to score new ideas and support smarter roadmap decisions.
Visual Context
AI performs better with context, so we gave Iris the ability to see.
Using a screenshotting API built on headless browser tooling, users can pass in a URL and Iris can:
- See the current webpage experience
- Suggest test ideas and analyze test results
- Identify UX or conversion opportunities
This has had an outsized impact on AI-powered A/B test ideation.
Security by Design
Security was a design constraint from day one.
Ask Iris uses JWT-based authentication across the entire stack, enforced at the infrastructure level. Access control happens before a prompt ever reaches a model.
That means:
- No data leakage
- No prompt injection shortcuts
- No reliance on polite model behavior for security
If a user should not see something, the system simply can’t retrieve it. Plain, simple, and secure.
What’s Next
Ask Iris is evolving from a data assistant into a true agentic partner for experimentation, supporting:
- Research
- Ideation
- Roadmap planning
- Spec writing
- Post-test analysis
The goal is straightforward: reduce busywork so growth teams can focus on higher-leverage thinking and make better decisions.
Ask Iris is only three months old, but we are excited about where it is heading.
I hope this peek under the hood helps others who are building RAG or agentic chat systems. Please reach out to me if you have questions.
Ready to turn ambitious growth goals into deeper customer connections and measurable business impact?
Reach Out Today